Harness engineering is the practice of building external controls — guides and sensors — around AI coding agents so they produce reliable code. Birgitta Böckeler's framework defines the theory. This article maps each concept to a working implementation: what maintainability, architecture fitness, and behaviour harnesses actually look like in production.
On April 2nd, Birgitta Böckeler published Harness Engineering for Coding Agent Users — a framework that defines what coding agents need beyond the model itself. Her thesis: to enable agents to operate with minimal supervision, teams must build systems of controls that steer agent behavior before it acts and observe it after.
We read it and felt something unexpected. Not surprise. Recognition.
Not because we read the paper first. Because the problem demands this architecture. When you spend enough time making AI agents produce reliable code in production, you converge on the same design — feedforward controls to constrain, feedback controls to correct, and a closed loop that gets tighter over time.
This article maps Böckeler's theoretical framework to a working system. Not to claim priority — the framework is hers, and it is excellent — but to show what each concept looks like when it is implemented, deployed, and shipping code every day.
The Core Insight: Agent = Model + Harness
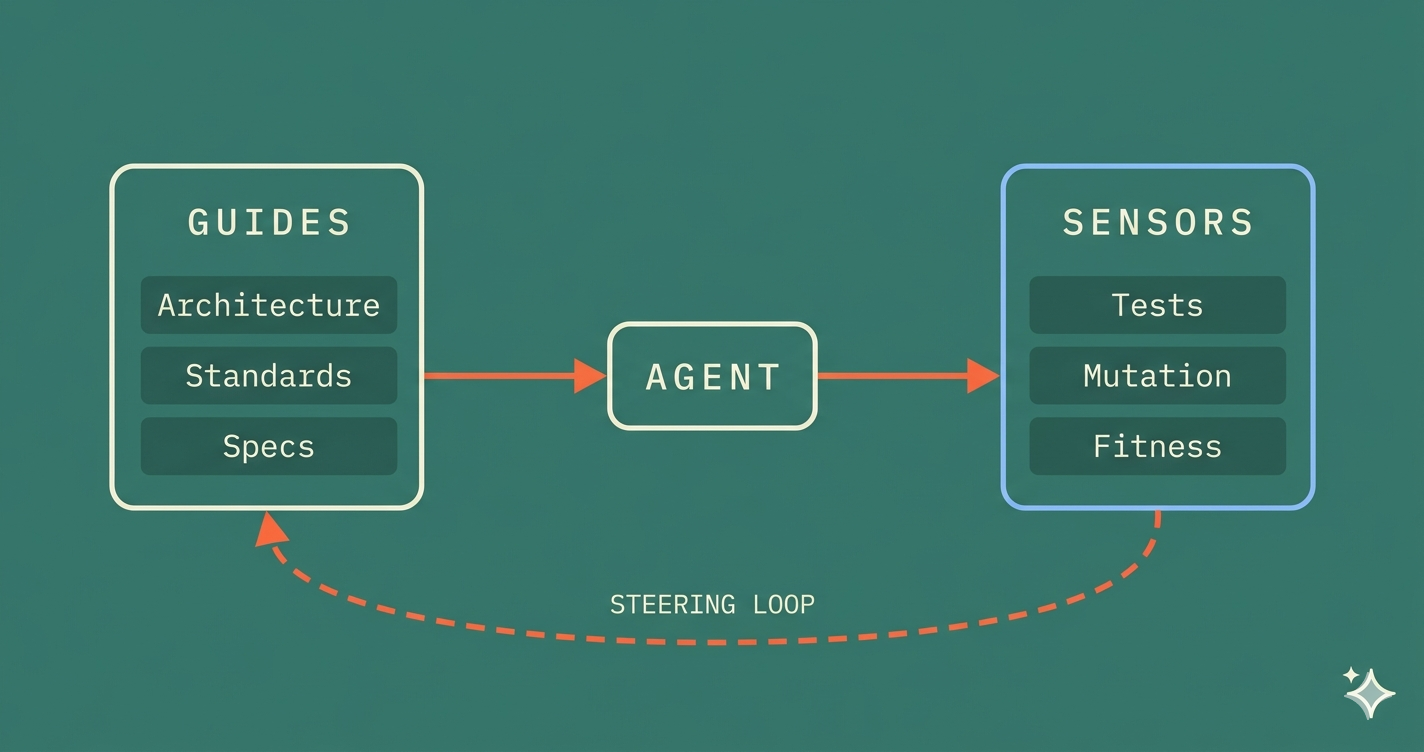
Böckeler defines a harness as "everything in an AI agent except the model itself." She draws a boundary around the user-facing controls that sit outside the coding agent's built-in systems. And she distinguishes two types:
- Guides (feedforward controls): Systems that anticipate agent behavior and steer it before action, increasing the probability of quality output on the first attempt.
- Sensors (feedback controls): Systems deployed after the agent acts to observe results and enable correction.

Figure 1: The harness model. Guides steer the agent before action. Sensors observe after. The steering loop (coral) connects sensor output back to guide improvement.
This maps to a concept we have been building around: Prevention, Detection, and Correction. The vocabulary is different. The architecture is the same.
Guides are Prevention — constraints injected into the agent's context at the moment of code generation. Sensors are Detection — automated verification at every stage of the pipeline. The steering loop is Correction — where sensor output feeds back to tighten the guides. Together, they form a closed-loop regulation system.
Two Execution Types
Böckeler makes a crucial distinction between two types of harness controls:
Computational controls run on CPU, execute in milliseconds to seconds, and produce deterministic results. Linters, type checkers, test suites, architecture fitness functions. You run them, you get a reliable answer.
Inferential controls use AI models, run on GPU/NPU, are slower and more expensive, and produce non-deterministic results. AI code review, semantic analysis, intent verification.

Figure 2: Computational vs. inferential controls. Both can serve as guides or sensors. A robust harness uses both — computational controls for speed and reliability, inferential controls for semantic depth.
The practical implication: lean on computational controls wherever possible. They are cheaper, faster, and deterministic. Reserve inferential controls for the problems computational controls cannot reach — semantic code quality, intent verification, requirement interpretation.
In a working harness, this looks like: architecture fitness functions (computational) catch 90% of structural violations instantly. AI code review (inferential) catches the remaining semantic issues — over-engineering, misunderstood intent, unnecessary complexity — but at higher cost and lower reliability.
Three Harness Layers
Böckeler defines three regulation categories, each addressing a different dimension of code quality. Each one maps to concrete implementation patterns.

Figure 3: Böckeler's three harness layers mapped to implementation. Each theoretical category has a concrete counterpart with specific tools and enforcement patterns.
Let us walk through each layer.
Layer 1: The Maintainability Harness
Böckeler's framework: Regulate internal code quality. Computational sensors (linters, type checkers, coverage tools) catch structural issues reliably. Inferential sensors (AI review) partially catch semantic issues but non-deterministically. Neither reliably catches higher-impact failures like misdiagnosis or misunderstood requirements.
What implementation looks like: This is the most mature layer because the tools already exist — what is missing is orchestration. A working maintainability harness does not just run linters. It runs them as part of a closed loop:
The guide side loads coding standards as agent skills — not as documents the agent might ignore, but as constraints injected into the agent's context at the moment of code generation. When the agent is about to write code, it has already absorbed the rules. This is feedforward: increasing the probability of correct output on the first attempt.
The sensor side uses mutation testing as the primary verification mechanism — not code coverage. Coverage measures whether lines were executed during testing. Mutation testing measures whether tests actually verify behavior. An agent can generate code that achieves 100% coverage with zero behavioral assertions. Only mutation testing catches that. And critically, this sensor runs during TDD — after the agent writes code to pass a test, mutation testing validates the test's effectiveness before the code is even committed. This is further left than most frameworks place it.
The steering loop closes when mutation survivors — the specific mutations that tests failed to catch — become new constraints. "This pattern was not caught by tests" becomes a rule for the next iteration. The harness learns from its own gaps.
Layer 2: The Architecture Fitness Harness
Böckeler's framework: Define and check architectural characteristics through fitness functions. Performance requirements paired with performance test sensors. Observability conventions paired with debugging instruction sensors.
What implementation looks like: This is where the concept of constrained topologies — which Böckeler calls "harness templates" — becomes essential.
Most architecture enforcement fails because it is advisory. A wiki page says "don't call the database from the controller." The agent does not read wikis. Even if you inject the rule as a guide, the agent may pattern-match on existing code that violates the rule — the three files a junior developer wrote during a crunch that bypass the repository layer.
A working architecture harness enforces boundaries structurally:
- The agent operates within layer-aware workflows. It cannot generate code in the wrong architectural layer because its workflow does not permit it. This is not a prompt instruction — it is a structural gate
- Dependency direction validation runs as a computational sensor on every commit. If module A depends on module B in the wrong direction, the build fails
- Circular dependency detection catches the coupling patterns that confuse both humans and agents
The critical insight is topology reduction. Böckeler references Ashby's Law of Requisite Variety: a regulator must have at least as much variety as the system it regulates. This is why opinionated architecture is a feature, not a limitation.

Figure 4: Ashby's Law in practice. An unconstrained agent can produce any structure — infinite failure modes that no harness can fully cover. A constrained agent operating within Clean Architecture layers has a finite, testable set of possible outputs.
By committing to defined topologies — Clean Architecture with explicit layers and dependency rules — you reduce the variety the agent can produce. The harness becomes achievable because the failure space is bounded.
An agent operating on an unconstrained codebase has infinite failure modes. An agent operating within defined boundaries has a finite, testable set. This is the single most important architectural decision in harness engineering.
Layer 3: The Behaviour Harness
Böckeler's framework: Address functional correctness — the least mature category. Current practice combines functional specifications (feedforward) with AI-generated test suites and coverage analysis (feedback), supplemented by manual testing. The "approved fixtures" pattern shows promise but remains selectively applicable.
What implementation looks like: This is the hardest layer and the one where the industry has the most work to do. Böckeler is right that it is immature. But it is also where the highest-leverage controls live.
A working behaviour harness uses three interlocking mechanisms:
Executable specifications serve as the primary feedforward control. These are specifications written in problem-domain language before code — not as documentation, but as the acceptance criteria the agent must satisfy. When the agent receives a task, it receives the specification. When it produces code, the specification runs as an automated test. If the specification fails, the agent cannot proceed.
Example mapping surfaces complexity before the agent writes a single line. It is the most underrated guide in the framework: structured discovery of business rules, boundary conditions, and edge cases before implementation begins. Each example becomes a concrete test case the agent must satisfy.
TDD as structural enforcement is the mechanism that binds the behaviour harness together. The agent writes a failing test first, then writes minimal code to pass it. This is not a suggestion. It is a workflow gate: the agent cannot proceed to implementation without a failing test, and cannot proceed to the next feature without green tests and a passing mutation threshold.
The "approved fixtures" pattern that Böckeler mentions — pre-approved input/output pairs as behavioral anchors — maps directly to test data builders and specification fixtures. The limitation she flags (selectively applicable rather than comprehensive) is real, but it is solvable through the steering loop: each new fixture narrows the behavior space the agent operates in.
The Steering Loop: Where Harnesses Get Smart
Böckeler's most important insight may be the steering loop: humans improve harnesses by responding to repeated failure patterns, enhancing both guides and sensors over time.
This is the mechanism that makes agent harnesses compound in value. Every failure that escapes the harness becomes a new rule.

Figure 5: The steering loop. Prevent constrains before action. Detect verifies after. Correct fixes failures. Learn converts failures into new constraints — tightening the Prevent layer for the next iteration.
Here is how the loop works in practice:
- A mutation survives — a specific mutation in production code was not caught by any test. That surviving mutant becomes a new test pattern: a concrete rule that the next iteration must address
- An architecture violation slips through — a dependency crosses a layer boundary. A new fitness function is added to the commit-stage pipeline, catching that class of violation permanently
- A specification gap causes a misimplementation — the agent built the wrong thing because the spec did not cover an edge case. A new example mapping question is added to the planning phase for similar features
In a working system, the agent itself helps build the harness. It can generate structural tests from codebase analysis, derive architecture rules from existing patterns, identify specification gaps from mutation testing results, and suggest new fitness functions when violations are detected.
This is the loop that closes the gap between "harness as configuration" and harness as learning system. The harness does not just constrain the agent — it learns from the agent's failures and gets tighter over time.
Timing: Quality Left — Further Than You Think
Böckeler introduces an important timing framework: distribute checks across the development lifecycle according to cost and speed. She places mutation testing in the post-integration pipeline — after code is committed, during CI.
We go further. In a working harness, mutation testing happens during TDD — at the pre-commit level, as part of the developer workflow. After the agent writes a failing test and then writes code to pass it (the Red → Green cycle), a mutation testing agent validates that the tests actually verify behavior before the code is committed. Surviving mutants are caught before they enter the pipeline, not after.
This matters because mutation testing is the sensor that distinguishes decorative tests from effective ones. If you wait until CI to discover that your tests do not catch bugs, you have already committed code with false confidence. Shifting mutation testing into the TDD loop means the agent gets real feedback at the moment of creation.
The broader timing model maps to three stages in a Continuous Delivery pipeline:

Figure 6: Quality Left — three stages of the CD pipeline, each with specific gates. The commit stage catches code-level defects. The release stage verifies contract compatibility. The acceptance stage validates system-level behavior.
Commit Stage (seconds to minutes, pre-integration): This is the fast feedback loop. Unit tests, component tests, narrow integration tests, contract tests, architecture fitness functions, and linting all run here. The gate is strict — code must pass every test layer before artifacts are built. Mutation testing runs during TDD before this stage even begins.
Release Stage (minutes, pre-deployment): The contract verification gate. Before any deployment, a can-i-deploy check verifies that the versions being deployed are compatible — consumer contracts match provider implementations. This prevents the class of failures where services deploy independently and break each other. Deployment only proceeds if contracts are verified.
Acceptance Stage (minutes, post-deployment): System-level validation against a production-like environment. Smoke tests verify connectivity and basic flows. Executable specifications (acceptance tests) verify user-facing functionality. Version tracking ensures tests only run when deployed versions change — no redundant runs.
Each stage catches a different class of failure. The commit stage catches code-level defects. The release stage catches integration incompatibilities. The acceptance stage catches system-level and environment issues. Together, they form a pipeline where quality is verified at every transition — not just at the end.
Harnessability: Why Some Codebases Are Easier to Harness
Böckeler introduces "harnessability" — the property of a codebase that determines how amenable it is to harness construction. Strongly-typed languages afford type-checking. Clear module boundaries enable architectural constraints. Frameworks reduce the agent's decision space.
She also introduces "ambient affordances" — structural environment properties that make systems "legible, navigable, and tractable to agents." These properties are easier to achieve in greenfield but are most critical for legacy systems where harnesses are most needed.
This is the AI readiness concept by another name. A codebase with clear boundaries, consistent naming, comprehensive types, and well-defined interfaces is both more harness-able and more AI-ready. A codebase with circular dependencies, god classes, and implicit conventions resists both.
The implication is practical: improving your codebase's harnessability and improving its AI readiness are the same investment. Teams that adopt Clean Architecture, enforce module boundaries, and write effective tests are simultaneously building the harness their agents need and the foundation their agents can work on.
This is why measurement must come before enforcement. You need to know your harnessability score — the current state of your architecture, your test effectiveness, your coupling metrics — before you know where to invest. Start with a diagnosis, then build the harness around the results.
What Harnesses Cannot Replace
Böckeler closes with something important: experienced developers bring implicit harnesses — absorbed conventions, intuitive complexity awareness, organizational alignment, and deliberate pacing that enables reflection.
Agents lack four things that no harness can fully replicate:
- Social accountability — the awareness that other humans will read, maintain, and debug this code
- Aesthetic judgment — the sense that something is over-engineered, inelegant, or doing too much
- Contextual intuition — the knowledge of why a decision was made six months ago and whether it still holds
- Organizational memory — understanding which trade-offs the team has already tried and rejected
The goal of a good harness is not to eliminate human involvement. It is to direct human expertise toward where it matters most. A senior engineer should not spend their time catching linting violations or architecture drift — the harness should catch those. The senior engineer should spend their time on the things the harness cannot do: evaluating trade-offs, questioning requirements, deciding when to break the rules, and improving the harness itself.
The Open Questions
Böckeler raises five questions that remain unsolved. They are worth naming because they define the frontier of this discipline:
-
Harness coherence — How do you prevent guides and sensors from contradicting each other as the harness scales? When one skill says "keep it simple" and another says "handle all edge cases," how does the agent navigate?
-
Conflicting instructions — How can agents sensibly navigate when two guides disagree? This is not a theoretical problem — it happens whenever architecture rules interact with performance requirements or security constraints
-
Silent sensors — How do you distinguish "no problems detected" from "the sensor cannot detect this class of problems"? A clean mutation testing report might mean great tests — or it might mean the mutation tool does not cover certain mutation types
-
Harness coverage — Is there a "mutation testing for harnesses"? A way to evaluate whether the harness itself is comprehensive? This is meta-regulation: testing the tests of the tests
-
Integration — How do you integrate scattered controls across delivery steps into a coherent system? Most teams have linters, tests, and review processes that do not talk to each other. Turning a toolbox into a harness requires integration that most CI/CD pipelines were not designed for
These are not academic questions. They are engineering problems. And solving them is the difference between a harness that works on a demo and a harness that works in production.
The Bottom Line
Böckeler's framework gives the industry a shared vocabulary for something many teams are building independently: the controls that make AI coding agents reliable. Guides steer before action. Sensors observe after. The steering loop makes both better over time.
The theory is now published. The question for every engineering team is practical: what does your harness actually look like? Is it a collection of scattered tools — a linter here, a test suite there, an architecture wiki nobody reads — or is it a coherent system where every control reinforces the others?
The teams that figure this out first will have agents that ship reliably. The teams that do not will have agents that ship faster chaos.
The framework is here. The implementation is possible. The only question is whether you build the harness before you deploy the agent — or clean up after it.

