AI coding tools like GitHub Copilot fail to deliver ROI when deployed on codebases without strong engineering foundations. Teams typically see increased defect rates, longer code review cycles, and higher technical debt — not faster delivery. The fix is not a better AI tool. It's building the architecture, testing, and specification foundations that make any AI tool effective.
The pitch was simple: give every developer an AI copilot and watch productivity soar.
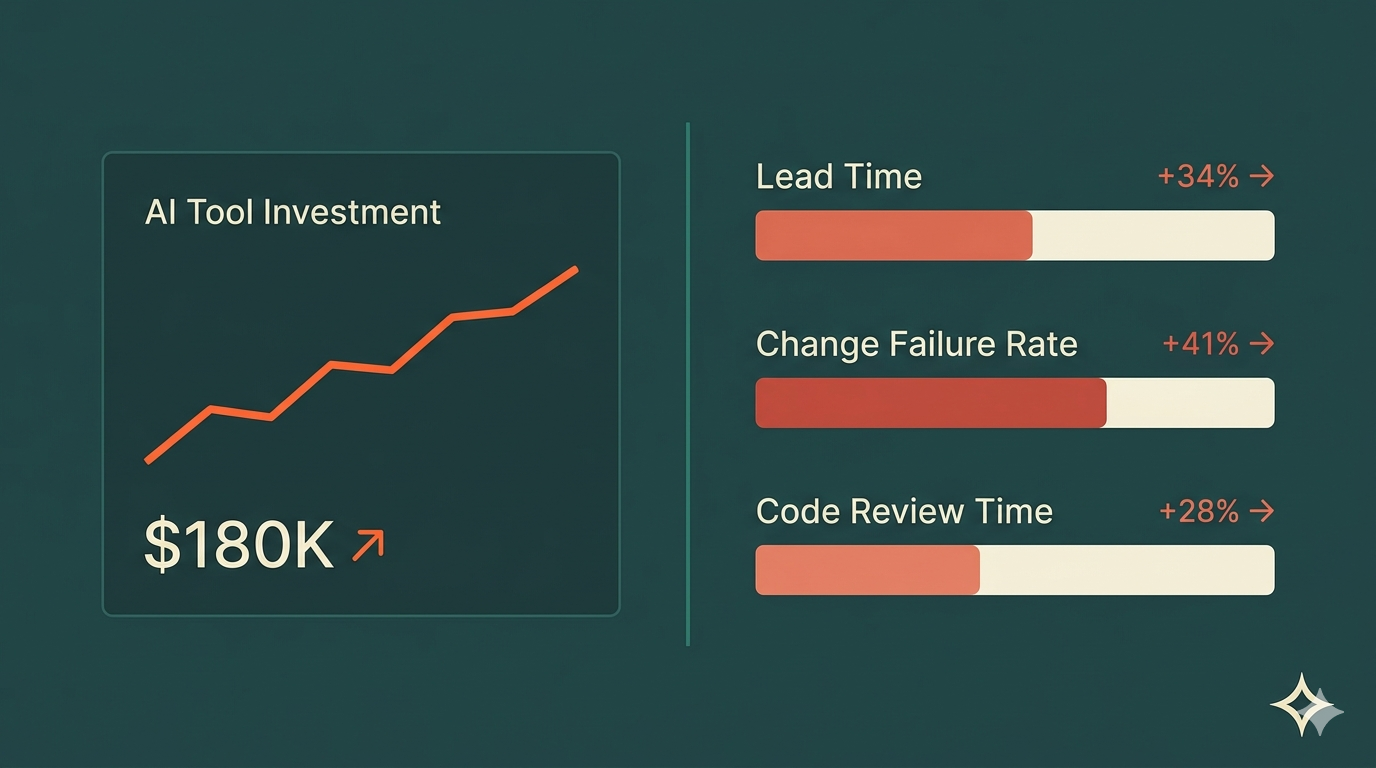
So you did. Fifty licenses at $19/user/month. Onboarding sessions. A Slack channel for tips and tricks. Six months later, the numbers tell a different story.
Lead time went from 12 days to 16 days. Change failure rate climbed from 18% to 27%. Your two best senior engineers are now spending 40% of their time reviewing AI-generated pull requests instead of building features. And the codebase? It gained 47,000 lines in six months — with no corresponding improvement in what you can actually ship.
You didn't buy a productivity tool. You bought a chaos accelerator.
The $180K Breakdown
Let's be honest about the real cost, because it's not just the licenses.
For a 50-person engineering team:
- License fees: $11,400/year (Copilot Business at $19/user/month)
- Increased review burden: Senior engineers spending 30-40% more time on code reviews. At $180K loaded cost per senior engineer, that's $54K-$72K per affected engineer
- Defect rework: Higher change failure rates mean more time fixing production issues instead of shipping features
- Technical debt accumulation: AI-generated code that bypasses architecture boundaries creates compounding maintenance costs
The license cost is a rounding error. The real cost is what happens to your engineering organization when AI-generated code meets a codebase that wasn't ready for it.
Why Copilot Made Things Worse
GitHub Copilot is an extraordinary piece of technology. It generates syntactically correct, often functional code at remarkable speed. That's precisely the problem.
The speed trap
Before Copilot, a developer would write a function, think about where it belongs, maybe check the existing patterns, write some tests. The pace was slow enough that judgment had time to operate.
With Copilot, code appears in seconds. The developer accepts the suggestion, moves on, and generates the next block. In an eight-hour day, a developer using Copilot produces 2-3x more code. But producing code was never the bottleneck.
The context problem
Copilot doesn't know that your team spent three months migrating from a monolith to a hexagonal architecture. It doesn't know that direct database access in the API layer violates your architecture decision records. It doesn't know that the UserService was supposed to be deprecated last quarter.
What it does know is patterns. And the patterns in your codebase include every shortcut, every workaround, every "temporary" fix from the last five years. Copilot learns from your worst code as enthusiastically as from your best.
The testing illusion
Here's where the real damage happens. Your team runs the test suite after every AI-assisted change. Tests pass. Green checkmarks all around. Ship it.
But are those tests actually verifying behavior? Run mutation testing on a typical enterprise codebase and the answer is sobering: 80-90% of tests would still pass even if you deleted the production code they claim to test. These are decorative tests — they exist, they run, they pass, and they prove nothing.
When Copilot generates code, runs the test suite, and sees green, it's getting false confidence from a false signal. The code ships. The bugs ship with it. Your change failure rate climbs, and nobody connects the dots back to the AI tool they just invested six figures in.
The Pattern Nobody Talks About
There's a deeper pattern at work. AI coding tools create a specific organizational dysfunction: they shift the quality burden upstream to the people least equipped to absorb it.
Before Copilot, your junior developers wrote code slowly. That slowness was a natural quality gate — they had time to think, and the small volume of code was reviewable.
After Copilot, your junior developers produce code at near-senior velocity. But they still lack the architectural judgment to know whether the generated code is correct. The volume overwhelms your review process, and your senior engineers become full-time reviewers instead of builders.
The result: your most expensive engineers are now doing the lowest-leverage work, your juniors are learning less (because they're accepting suggestions instead of thinking), and the codebase is growing faster than anyone can understand.
What the Fix Actually Is
The fix is not a better AI tool. It's not prompt engineering workshops. It's not an AI code review bot to review the AI-generated code.
The fix is building the foundations that make AI tools effective.
1. Measure test effectiveness, not coverage
Stop looking at coverage numbers. Start running mutation testing on your critical paths. If your mutation score is below 50%, your test suite is lying to you — and by extension, lying to every AI tool that uses it as a feedback signal.
When tests actually catch defects, AI tools get real feedback. They stop shipping bugs with the confidence of a green pipeline.
2. Enforce architecture boundaries automatically
Your architecture decisions need to be checked on every commit, not documented in a wiki. When boundaries are enforced — no circular dependencies, explicit module contracts, dependency rules that break the build — AI-generated code either lands in the right place or gets rejected immediately.
This turns Copilot from a chaos accelerator into a constrained generator. It can still produce code fast, but only code that fits your architecture.
3. Write specifications before code
AI tools are extraordinarily good at satisfying tests. The question is whether those tests capture what you actually need. When specifications are written in problem-domain language before code, the tests that flow from them define real acceptance criteria — not implementation details.
Copilot generating code that satisfies a real specification is valuable. Copilot generating code that satisfies a decorative test is expensive noise.
4. Measure delivery outcomes, not code output
Stop celebrating lines of code produced. Start measuring what matters: lead time for changes, deployment frequency, change failure rate, and mean time to restore. If these metrics aren't improving — or are getting worse — your AI investment is not working, regardless of how much code is being generated.
The Teams That Get It Right
Not every Copilot investment fails. The teams that see genuine ROI share three characteristics:
-
Their test suites catch real defects. Mutation scores above 70%. AI-generated code that breaks something gets caught immediately, not in production.
-
Their architecture is enforced, not documented. Dependency rules, module boundaries, and interface contracts are checked automatically. AI-generated code that violates architecture gets rejected before review.
-
Their specifications exist before code. The AI is generating implementations for well-defined problems, not guessing at requirements.
These teams see lead times drop by 40-60%. Their change failure rates hold steady or improve. Their senior engineers stay focused on architecture and design instead of reviewing AI-generated pull requests.
The difference isn't the tool. It's what the tool has to work with.
The Bottom Line
Your $180K Copilot investment didn't fail because Copilot is bad. It failed because your codebase wasn't ready for what Copilot amplifies.
AI coding tools are accelerators. On strong foundations — clean architecture, effective tests, clear specifications — they accelerate delivery. On weak foundations, they accelerate the production of technical debt, defects, and organizational dysfunction.
Before you renew those licenses, ask yourself: did we invest in the foundations, or just the tool?
The answer to that question is worth a lot more than $180K.

